All Posts
76 posts sorted by latest.
devops
3 min read
We analyze the reasons why hard cuts lead to failures in L4 Load Balancer and Nginx-WebSocket architecture from the connection lifecycle perspective.
devops
4 min read
We dissect what connection state changes actually occur in L4 Load Balancer by bind, unbind, and connection draining based on the TCP lifecycle.
devops
4 min read
We decompose Connection Draining into TCP lifecycle and explain how SYN, FIN, RST, TIME_WAIT, and CLOSE_WAIT appear in actual operational indicators.
devops
4 min read
The phenomenon of connection draining not ending due to WebSocket persistent connection is analyzed from the perspective of TCP, Nginx proxy, and application, and five solutions are presented.
devops
4 min read
The Zero Downtime Deployment procedure that can actually be operated in the L4 -> Nginx -> App -> WebSocket architecture is presented in a 7-step runbook.
devops
3 min read
Actual failure patterns caused by server removal without drain, WebSocket drain failure, and keepalive setting imbalance are analyzed through symptoms, logs, causes, and solutions.
devops
4 min read
We present a practical checklist to verify Connection Draining and Graceful Shutdown readiness within 10 minutes immediately before deployment in the L4/Nginx/App/WebSocket structure.
spring-boot
3 min read
We decompose Spring Boot deployment from an operational architecture perspective rather than comparing features, and provide criteria for which deployment model to choose.
spring-boot
3 min read
We present practical tuning standards that stably optimize batch throughput within system limits rather than blindly increasing it.
spring-boot
3 min read
We organize failure classification, DLQ, retry, and idempotency patterns to design deployment failures into a recoverable state rather than avoidable ones.
spring-boot
3 min read
We present a final decision matrix and reference architecture that combines @Scheduled, Quartz, Spring Batch, and manual deployment to suit actual operating conditions.
spring-boot
3 min read
The redundant execution, distributed locks, and failure recovery trade-offs that occur when applying @Scheduled to the operating environment are organized based on architecture.
spring-boot
3 min read
This course covers JobStore, Misfire, and cluster design standards for using Quartz as an operational control system rather than a simple scheduler.
spring-boot
3 min read
We dissect Spring Batch's Reader/Processor/Writer structure from an operational perspective and present standards for designing a restartable batch.
spring-boot
3 min read
Spring Batch parallel processing strategies are compared in terms of throughput, order guarantee, and operational complexity, and selection criteria are presented.
spring-boot
3 min read
We summarize API design, permission control, audit trail, reprocessing, and rollback strategies to safely operate manual deployment.
spring-boot
3 min read
We present paging/index/isolation level design standards to simultaneously secure DB query performance and consistency in mass deployment.
spring-boot
3 min read
We summarize the OpenSearch deployment design criteria and operational trade-offs considering both bulk querying and mass indexing from a practical perspective.
spring-boot
3 min read
We present criteria for selecting an execution entity/lock strategy to prevent duplicate execution of batches in multi-instances and control operational complexity.
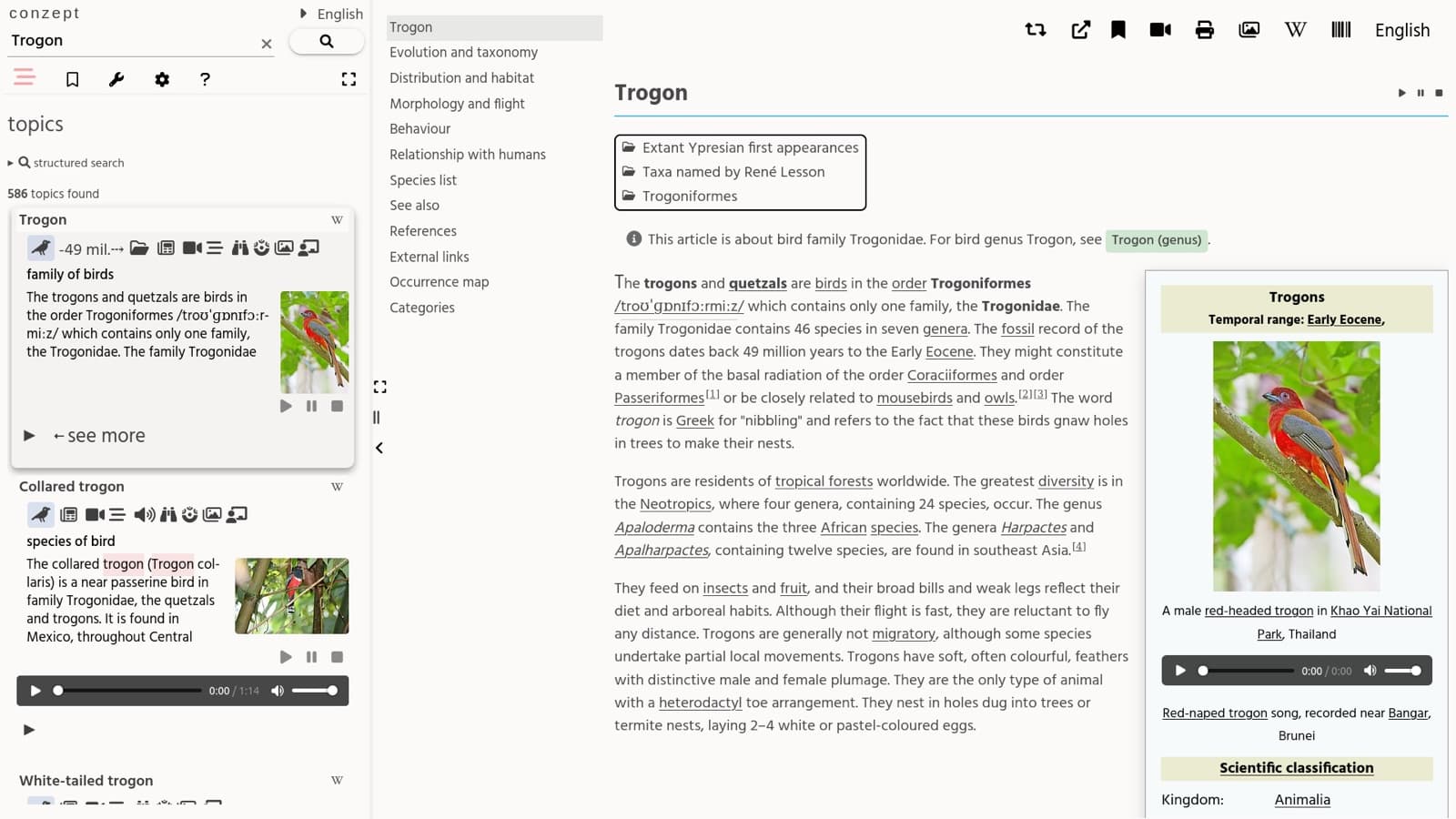
2 min read
Server Actions A practical guide that improves operational stability by separating input verification, authority checking, and error mapping.

2 min read
Content model, frontmatter policy, and series structure design method for long-term operation of a file-based technology blog

3 min read
Robots/sitemap/structured data/index operation strategy to increase Google, Naver, and Daum search exposure
3 min read
Ad placement, loading strategy, and monitoring standards to protect Core Web Vitals and UX while applying AdSense
llm
4 min read
From a system perspective, we summarize that the essence of the LLM function is not the prompt statement itself but the boundary, contract, state, and failure handling.
llm
5 min read
LLM quality is stabilized when managed through datasets, evaluation criteria, online feedback, and regression detection loops, not sentence tuning.
llm
4 min read
We summarize the reasons and operating patterns for retries, timeouts, fallbacks, and circuit breakers in LLM systems that should be designed differently from regular APIs.
llm
4 min read
LLM costs are determined by the system control method, not the model unit price. Organize cache, batching, routing, and token budget from an operational perspective.
llm
4 min read
LLM security is not solved by prompt defense alone. Covers system design that combines permission policies, data boundaries, and tool sandboxing.
llm
4 min read
To catch quality degradation without failure in LLM operation, trace, log, and quality indicators must be designed as a single observation system.
llm
4 min read
LLM quality is more sensitive to the context path than the model. We summarize how to design RAG, memory, freshness, and tenant boundaries from a system perspective.
llm
4 min read
Operable agents are state-based systems, not chains. Planner/Executor separation, queues, guardrails, and recovery strategies are organized from a practical perspective.
llm
5 min read
It covers failure UX, human intervention, and operational governance design to make a technically functional LLM function into a trustworthy product for users.
llm
4 min read
We summarize why different deployment gates are needed for each type of change in LLM operations, as well as experiment, canary, and rollback strategies.
llm
4 min read
We present an LLM/Agent reference architecture that combines prompting, evaluation, reliability, cost, security, and observability into one operating system.
llm
5 min read
We present an organizational structure, role separation, decision-making system, and maturity roadmap to operate the LLM/Agent system sustainably.

3 min read
Practical design guide to simultaneously secure cache hit rate and data freshness by using Redis tag cache in Next.js App Router

2 min read
staleTime, persistence, and sync patterns to implement cache-first UX in unstable network environments

2 min read
A practical guide organizing the Seoul forecast for Tuesday, March 3, 2026 by time zone: precipitation at dawn, cloudy in the morning, clear in the afternoon.
2 min read
A practical guide that organizes indicator interpretation, code integration, and improvement loops to use Vercel Analytics as a decision-making tool in the early stages of blog operation.

2 min read
How to simultaneously manage bundle size and complexity by dividing React Server Components boundaries into functional units

2 min read
An operating method that blocks performance regression at the release stage by budgeting LCP, INP, and CLS targets

2 min read
Form component structure that maintains screen reader, keyboard navigation, and error notification consistency

2 min read
How to implement per-user call limits with Sliding Window and reduce false positives and misses
3 min read
A practical guide to designing an App Router-based blog MVP from a Clean Architecture perspective and organizing layer responsibilities and infrastructure trade-offs

2 min read
Query optimization guide to reduce feed API latency with complex indexes and execution plan interpretation

2 min read
Outbox pipeline design that simultaneously ensures transaction consistency and event delivery reliability

2 min read
Organizing key scope, TTL, and response reuse policies to safely handle duplicate requests

2 min read
Boundary design that controls operational complexity while maintaining gRPC on the inside and REST on the outside

2 min read
Guide to selecting Saga patterns for distributed transactions, considering failover, traceability, and team structure

2 min read
Flag life cycle and observation indicator operation method to automate staged deployment and rollback

2 min read
How to design autoscaling based on user experience indicators, moving away from CPU-centric scaling

2 min read
An operating pattern that determines promotion/discontinuation by automatically determining error rate and delay time in gradual deployment
2 min read
A hands-on pipeline that manages MDX frontmatter verification, rendering, and deployment stability all at once in a Next.js file-based blog.

2 min read
Step-by-step strategy to reduce downtime risk by decoupling application transitions from schema changes

2 min read
Measurement standards that connect logs, metrics, and traces to reduce time to cause of failure

2 min read
How to create a consistent response flow from alarm reception to communication, recovery, and post-analysis

2 min read
An operation guide that increases DR reliability by not only completing backups but also including recovery rehearsals

2 min read
How to reduce infrastructure change risk by automating IaC module standards, version strategies, and policy checks

2 min read
How to reduce pipeline time by separating dependency cache and build artifact cache

2 min read
Step-by-step conversion strategy required when expanding existing password/OTP-based authentication to Passkey

2 min read
Account takeover response method through refresh token reuse detection and session invalidation policy
2 min read
Practical checklist that organizes build verification, environment variables, and SEO output inspection procedures to stably deploy Next.js blog to Vercel.

2 min read
How to establish CSP policy step by step from Report-Only to Enforce conversion

2 min read
Practical operation guide that reduces the risk of confidential information exposure by combining environmental variables, vault, and KMS

2 min read
How to improve RAG quality by measuring the correlation between document segmentation rules and search accuracy

2 min read
Standard for managing search quality by interpreting Recall@K, MRR, and NDCG according to the service context

2 min read
How to reduce agent malfunctions by defining tool invocation privilege scope and failure recovery strategies

2 min read
A practical method to quantitatively track quality changes by operating prompt changes on an experimental basis

2 min read
Design that maintains quality and reduces inference costs by separating scheduling and model selection criteria

2 min read
A data team collaboration method that manages schema changes through contracts to prevent downstream failures

2 min read
Structure that clearly separates UseCase and Infra boundaries to suppress increase in complexity when expanding functions

2 min read
A DDD approach that ensures team scalability without oversplitting domain boundaries too early.

2 min read
How to reduce communication failures after deployment by verifying the provider/consumer contract at the CI stage

2 min read
Strategies to reduce monorepo build time through change impact calculation and cache key design

2 min read
Designing limits, buffers, and retries to protect the system from producer-consumer rate imbalances.

2 min read
How to connect technology and budget decisions through unit-of-service cost visualization